APACHE CASSANDRA DATABASE 4 PROBLEMS THAT CASSANDRA DEVELOPERS & ADMINISTRATORS FACE
We sat down with Khurram M. Pirzada, Big Data practice lead at Allied Consultants to ask him about the main challenges that developers come across an Apache Cassandra database (and NoSQL databases in general). Here are the major issues, along with their solutions that Pirzada highlighted.
1. Read-time Degradation
“Relational databases cannot handle very large stream of data because of their inherent design. An RDBMS’s performance is compromised as the volume of data increases” says Khurram Pirzada. At the start of its deployment stages, Cassandra remains fast. Over the course of time, the rows of data get spread out, eventually resulting in tombstones. The issue has also been discussed by Hadoop & Cassandra practitioners at the 2013 Cassandra Summit. Michael Kopp, Technical Product Manager at Ruxit, observes that “the degradation problem can be attributed to the wrong schema design and wrong access pattern”. An even worse problem arises in adding and removing columns in the same row over time that results in not only the row being spread out, it also leads to degradation of average performance.
Download Free Big Data Software Requirement Guide Here
How do you manage this issue when operating the Cassandra DB?
“Cassandra developers should not delete data, whether it is in-memory or stored in the data warehouse”, observed Pirzada. “The practice of deleting data as a general pattern should be avoided”, he added. Do not overwrite on the data tables; developers should make new data tables. Also, avoid writing to the same row over a long duration of time.
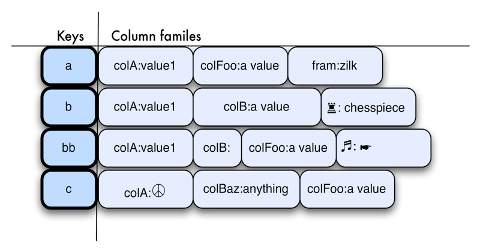
Pirzada also observed that whenever operators and administrators set-up NoSQL DBs, there are some parameters that the DB has to follow. “So, multiple patterns should be triggered (data fetching, storing, or loading)”, he observed. Kopp has also touched upon this issue of cluster performance degradation. He highlights the importance of choosing baseline Cassandra as it reads requests on a per column family basis.
2. Slow nodes can result in bringing down the cluster
There are three main reasons that may slow down the nodes in Cassandra (there are 256 virtual nodes per server by default). “Firstly, the infrastructure may not be supportive, or the schema may not match the data stream and lastly, the data types have such a huge variety that DB instances can have their tanks filled very quickly that slows down the cluster” observed Pirzada.
Hardware compaction and slow network directly triggers the performance issues in Cassandra. A coordinator queue resides in every node that waits for all requests to finish. The queue can fill up due to one slow node, and this can lead to unresponsiveness of the entire cluster to any incoming requests.
How can the developers and administrators maintain a healthy cluster performance?
Using time and process stamping usually addresses this issue successfully. “If you time stamp the data, it will process the whole data in 5 seconds and then leave it. Process stamp (similar to time-stamping approach) completes the first process and then proceeds on the 2nd process”. Using the token-aware client can bypass the coordinator problem. Astyanax is a token aware client used as a high level Java client for Cassandra.
- Baseline the response time of Cassandra requests on server nodes.
- Be on alert in case a node slows down, if there is a condition except the above two, it starts searching for the problem.
3. Failed operations
How does a failed operation impact the system?
A response is generated when a data chunk gets stuck due to any latency issue. However, in case the batch processing continues, data generation continues and data placement becomes a major issue. Both hardware and software can impact each other. Sometimes the hardware latency impacts the software performance or the software may relay wrong triggers that can choke the hardware.
Industry practitioners have extensively spoken about the issue of operational failover. Srinath Perera, Sr. Software Architect at WSO2 Inc. says that Cassandra supports idempotent operations instead of atomic operations, which means that the system remains in the same state, irrespective of how many times the operations are carried out. Other than that, Cassandra supports batch operations and since these operations are idempotent, they may leave side effects.
How should the Hadoop stack administrators address this challenge?
The users need to keep trying until all operations are successful, this is usually the issue of DevOps, so keep testing to check if the issue is arising from software or hardware (also known as test automation grill).
4. High frequency of read round trips
Cassandra database is designed in a way that it leads to transactions that make too many requests per end user. Making excessive requests and reading more data slows down the actual transaction, resulting in latency issues.
How can users address the issue of frequent read round trips?
Monitor and discover the issue with an APM (application performance management) solution which strives to detect and diagnose complex problems to maintain an expected level of service. Developers should opt for a change of code and data model, frequency of read write requests can be restricted or controlled.
Sources
Interview with Khurram M. Pirzada, Big Data Practice Lead at Allied Consultants
4 Reasons Why Data Engineers Don’t Use Cassandra by Patrick McFadin
Application Performance Management Blog
Related Posts
 Hadoop Foundation III: Laying the architecture & tools that compliment Hadoop
Hadoop Foundation III: Laying the architecture & tools that compliment Hadoop Hadoop Foundation II: What type of data Hadoop can help me with?
Hadoop Foundation II: What type of data Hadoop can help me with? Big Data Skills: The super-set of a Data Scientist’s skills
Big Data Skills: The super-set of a Data Scientist’s skills- Data Scientists and Justin Trudeau: 5 amazingly common things between the Canadian PM and data scientists
 Big Data – Weekly News
Big Data – Weekly News Big Data – Weekly news
Big Data – Weekly news