Use Case: In Search of the best OCR Applications
A client recently asked us to integrate scanned documents with information in their ERP (Sage X3). The requirement was to read documents similar to the ones below, parse information out of them, arbitrate through a user if we can’t read something automatically, run some business rules on it and integrate it with the ERP and all the business rules therein.
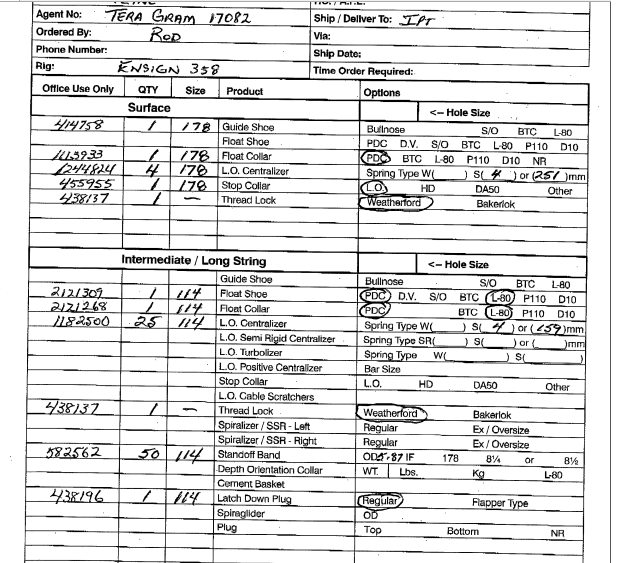
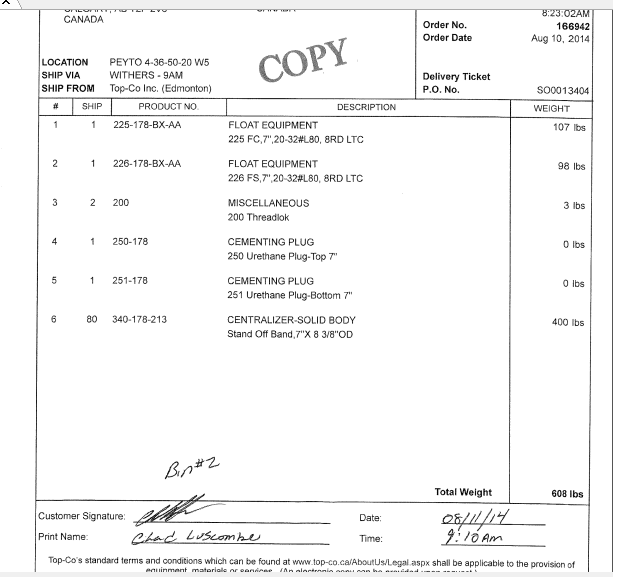
Now these are probably one of the more civilized samples but there are more nasty ones. We arent an OCR company and there are many options out there so we set about systematically collecting information and choosing the best available option out there. We started by breaking down the requirements into capabilities that we would need to parse things. These are not unique to our requirements and are rather typical in most OCR/OMR scenarios.
- Hand Written text: The ability to parse hand-written text.
- Tables: The ability to read data from tables and understand that they exist as rows and columns of connected information
- Circled text: There are forms where the user is circling pre-printed choices. The OCR tool needs to indicate a certain text was encircled so the selection can be deduced.
- Checkboxes: The ability to understand there is a checkbox and that it has been ticked or crossed or colored in.
- Printed text: The ability to read and parse text printed through a printer (in various fonts) and read them in as text.
- Bar code: The ability to read 2D bar codes
- Bar code inline with text: The ability to read bar codes with inline text.
- Ignoring regions/Stamps etc: Ignoring certain regions to not parse. These include things like signature areas or places where stamps were applied. Potentially these could be dynamic.
- Template support: The OMR API need to read off a template (ideally an empty version of the same form) to improve the accuracy of reads.
- C# SDK Support: Since we are Integrating the output of the OCR API with Sage X3, we needed to have an API available that could be triggered and/or parsed in C#.
- White on black background: While most text is black on a white page, there are cases where white text shows up on black backgrounds. The API needs to automatically understand this.
- Low DPI reads: Not all text is scanned perfectly. Sometimes users use low DPI settings on the scanner to scan files
- Ignoring background lines: Ignore lines for e.g. surrounding tables.
- Multi-Page: Be able to read for e.g. that a table has rolled over to a consecutive page.
- Auto-rotate: Rotate pages by 90 degrees or a 180% to read text. i.e. work with multiple page orientations.
- Dictionary support: When scanning, rather than at the entire English language dictionary it should limit itself to a user-defined subset. For e.g. the unit-of-measure should be ‘cm’, ‘m’,’ft’ etc.
- Provides text location metadata: For data elements it is unable to scan automatically or partially, it is very useful to have information available on where on the page a certain element existed. This was a good to have.
- License Cost: It needed to be affordable. Free ideally 🙂
- Expected accuracy: We needed a 90%+ match accuracy for our samples for the project to be business feasible
We looked at the following
- ABBYY – Fine Reader
- ABBYY – Flexi capture
- MiniPDF
- Online OCR.NET
- Simple OCR
- Nuance
- Free-ocr.com
- Cvision
- Aspose.NET OCR
- OCR-IT.com
- Form Storm
- OmniPage SDK
- Tesseract (google)
The summary of these is detailed here:
In summary probably one (if not THE) best one out there is ABBYY. Their engine and tools are probably one of the most advanced if you can afford them.
Allied Consultants is a solution design and implementation firm specializing in the integration of systems, devices, and processes. The article is a brief summary of what we did here. We’d be glad to share details if you feel you have similar issues or are just interested in more information.