Resource Management in Docker – An Overview
Resource Management in Information Technology
There is a whole host of technology available nowadays to ensure that your IT hardware resources manages efficiently. You may have a data center in-house, and a few cloud nodes/services/apps which together may constitute your investment in hardware. That would translate to resource capacity: memory, disk, and processor.
In the past, you’d purchase a machine and deploy an application on it. It may, or may not consume the resources of the application. Typically these resources were set for peak capacity and most of the rest of the time the machines would sit idle accruing capital investment costs.
Resource Management through Virtualization
Then came virtualization. Virtual machines would typically contain an OS, app, and their dependencies. Microsoft shipped special versions of windows to manage and host these technologies under the Hyper-V brand. But even with this, the VMs were bulky chunks of repetitive OS bits that weren’t required on all nodes.
The stingy guys are resource central and felt a finder level of management was possible and introduced containers. A container is a miniature version of the VM in that it (generally) doesn’t contain an OS. It only contains the bits required to run an application and a little more. But each container is a complete environment on its own (usually stateless). That made it lightweight and that meant you could fit more of these into the same resources. It also made application deployment and scale-out much simpler by viewing the app as a self-sufficient, completely independent black box (container) that a resource manager (like docker) can move around, start and stop as needed.
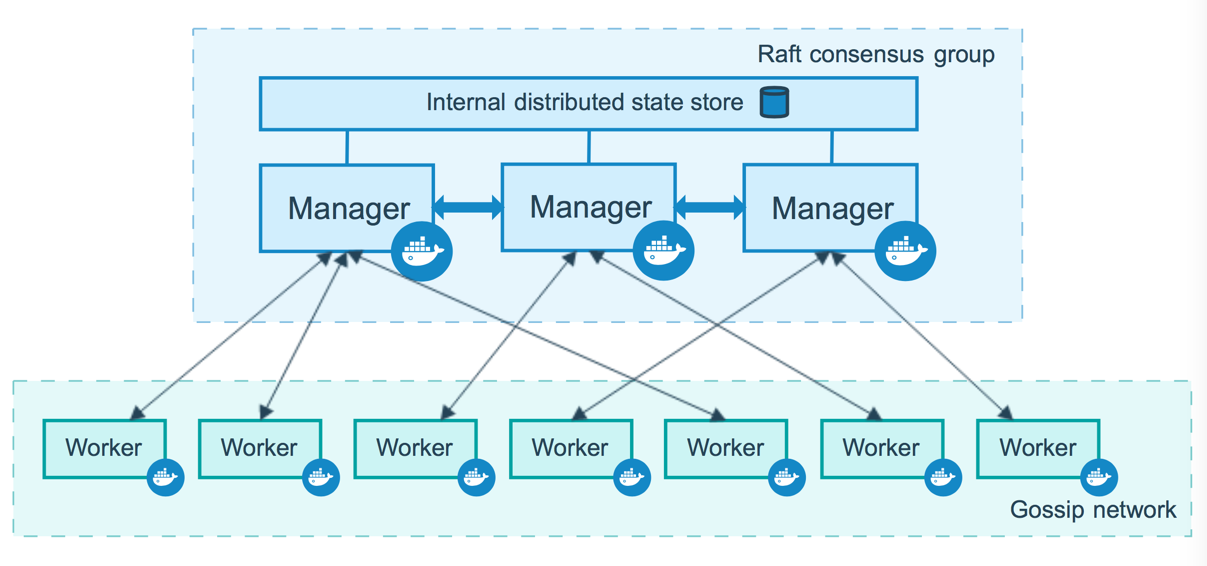
Key technologies here are docker (for container creation and execution), docker swarm (to automatically create a cluster of containers that act as one), and Kuberneties. There is much excitement around Kuberneties because it promises to provide a single platform to host containers that can run on multiple cloud providers, open stack, and bare metal. This brings about an interesting possibility of having a certain (cheaper) fixed capacity in-house along with some elastic cloud capacity all consolidated under one platform. This is still in the making though (a few years old) and is still very fixated on Linux (unlike VMs)
But they didn’t stop there. Frameworks like YARN and Mesos take the idea of application scale out further by having even more fine fine-grained of how an application scales out and how a cluster resources. YARN for e.g would restrict the idea of an app to a java JAR file (a map Redmap-reduce compiled code), which it can then micro-manage. YARN lets you manage in what sequences, priority, etc. the resources should be available between jobs. E.g. Round Robin, Fair or cap, city schedulers. Separate but tightly integrated with these are service registries like zookeeper that let you keep some sanity about all this through its service registry.
Conclusion
Now, practically speaking, most of the apps out in the business world (at least the ones I have seen) don’t need to be massively scaled out. While all this is very promising and academically quite interesting, there are many reasons why a single platform that hosts all the company’s IT applications are not like to happen immediately. Still, something to follow and keep track of though because all this tech is coming up fast and is making sense.