Big Data Skills: The super-set of a Data Scientist’s skills
It all began when participants in our Big Data training started yawning, apparently out of their want of a live action-packed big data assignment. A training was getting them bored since they wanted to jump into the sexiest job of the 21st century.
But, when it came to a live assignment, faces started turning pale white. It was not about writing the next script or code. It was about a more holistic skill set that data scientists rely upon. While the participants are still struggling with their assignments, I decided to delve deep into the type of skills that data scientists typically bring with them. A lively three-hour huddle with our Data Science Lead gave me a good understanding of what is required of data science and big data professionals. I’ll share with you what I learned about the skills needed to become a data scientist.
1. Maths/Statistics
Set theory
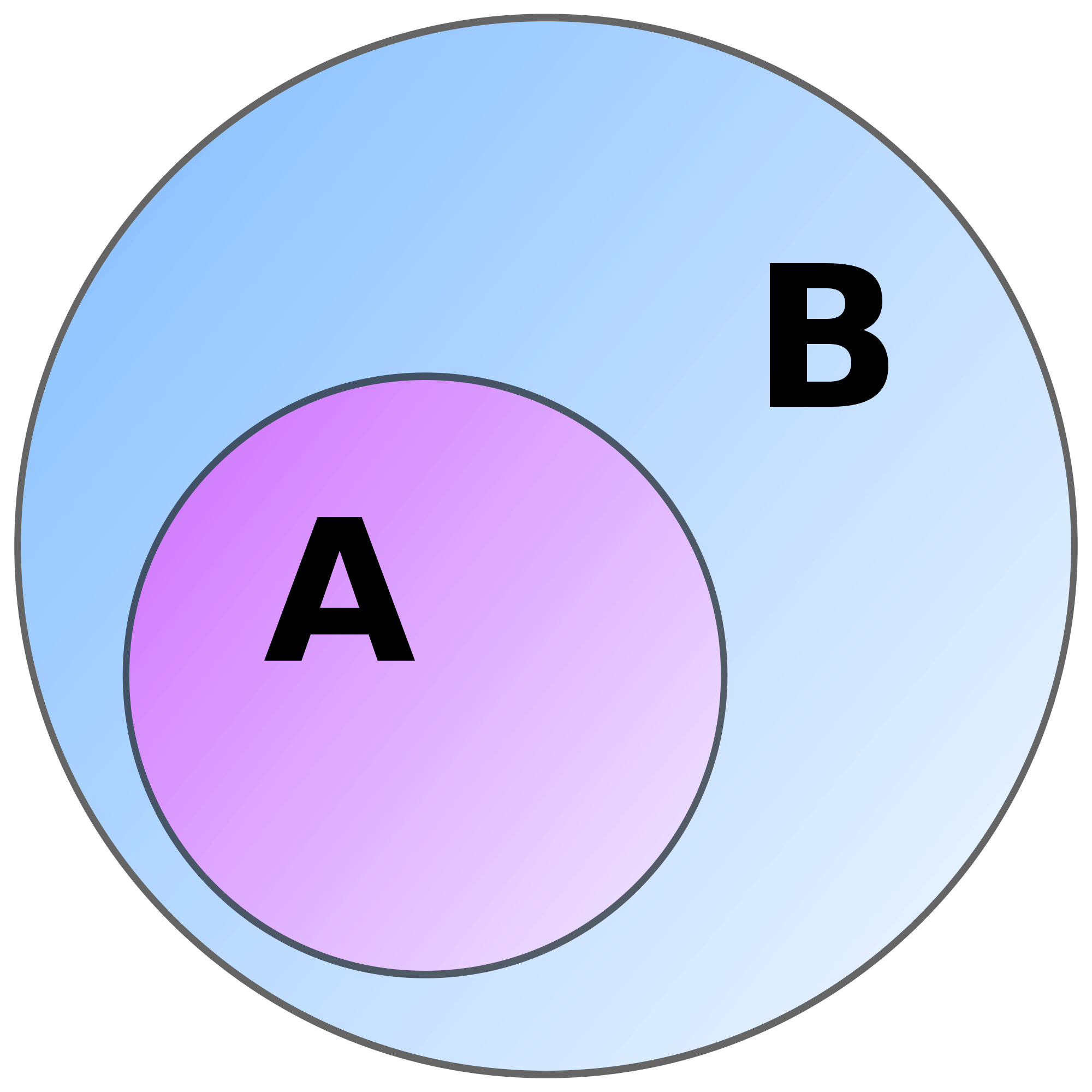
Simply put, set theory deals with the part of mathematical logic that studies sets. Sets are essentially an informal collection of objects. It is the foundation of mathematics, and you will see big data applications that use various flavors of set theory such as classical set theory, rough, fuzzy, and extended set theory. It is applied both in SQL and NoSQL databases.
Use-cases: It is heavily used in decision analysis, DSS (decision support systems), AI (artificial intelligence), ML (machine learning) and knowledge discovery from databases [1]. Specific applications include analysis and reduction of data for event prediction, data mining, and demand analysis in travel & supply chain industry. Data scientists also use it to analyze time-series data. Ken North has put forth a good explanation of using extended set theory (XST) in big data applications.
Numerical Analysis
Data scientists use numerical analysis to obtain approximate solutions while tolerating reasonable margin of error. You’ll be using a lot numerical linear algebra when performing data analysis.
A good handle on algorithms that use the numerical approximation always differentiates a data scientist. Traditional numerical calculations are not sufficient to scale the numerical algorithms and may need the use of advanced techniques within Big Data context.
Use-cases: Techniques such as matrix function evaluation and trace approximation are used to develop scalable numerical algorithms. Automobile manufacturers use advanced numerical techniques during rapid soft-prototyping. You’ll be dealing with broad numerical analysis techniques such as:
- Differential calculus
- Group theory
- Set theory
- Regression
- Information theory
- Mathematical optimization
Statistical methods
Statistical analysis involves creating correlations using the interpolation or extrapolation techniques for random and noisy data. Become familiar with statistical tests, distributions, maximum likelihood estimators, etc.
Use cases: Computational statisticians use the statistical techniques to scientifically discover patterns and trends. Some of the popular techniques are:
- Association rules
- Classification
- Cluster analysis
- Regression & multiple regression analysis
- Time-series analysis
- Factor analysis
- Naive Bayes
- Support vector machine
- Decision trees and random forests
- LASSO (least absolute shrinkage and selection operator)
Linear/Non-Linear algebra
Doing big data, you’ll come across curves, straight lines and other oscillations formed by doing data analysis. Linear algebra is about vector spaces and linear maps between these spaces.
You’ll deal with all things lines, planes, subspaces and properties associated to vector spaces. Non-linear algebra is about polynomial equations in which output is not always directly proportional to the input. You’ll be using both.
Most real world problems and systems are non-linear, but they are approximated using the linear equations.
Use cases: Linear algebraic equations are used in a set of methods and tools to extract meaningful information or patterns from data. Broad area: data analysis, machine learning, pattern recognition, information retrieval [2]. Non-linear methods and equations will be used in dimension reduction.
2. Computing
Software engineering 

A bachelor’s degree is more than enough since companies will most likely require you to make meaningful data like contributions to the production code. Computer science background will help you provide basic insights and analyses to the decision makers. Also, you’ll need a good dose of software skills (in languages that are mostly open-source) to engineer a strong data foundation.
Use cases: Ian Gorton observed that due to the distributed nature of big data and data science systems, you’ll be expected to make your system design tolerant enough for unpredictable communications latencies, consistency, partial failures, concurrency, and replication. Writing scripts, code and data tuning will help you lay the foundation for machine learning. Think of yourself as an architect when you perform the software engineering role.
Algorithms
This is the programming version of mathematical logic as the core of algorithms is logic. Optimum and real-time algorithms are used to process data, perform calculations and run automated reasoning. At a very basic level, algorithms are used for sorting and searching. An understanding and experience of using the graph and string-processing algorithms helps develop, tailor and implement these in real-world data science problems. 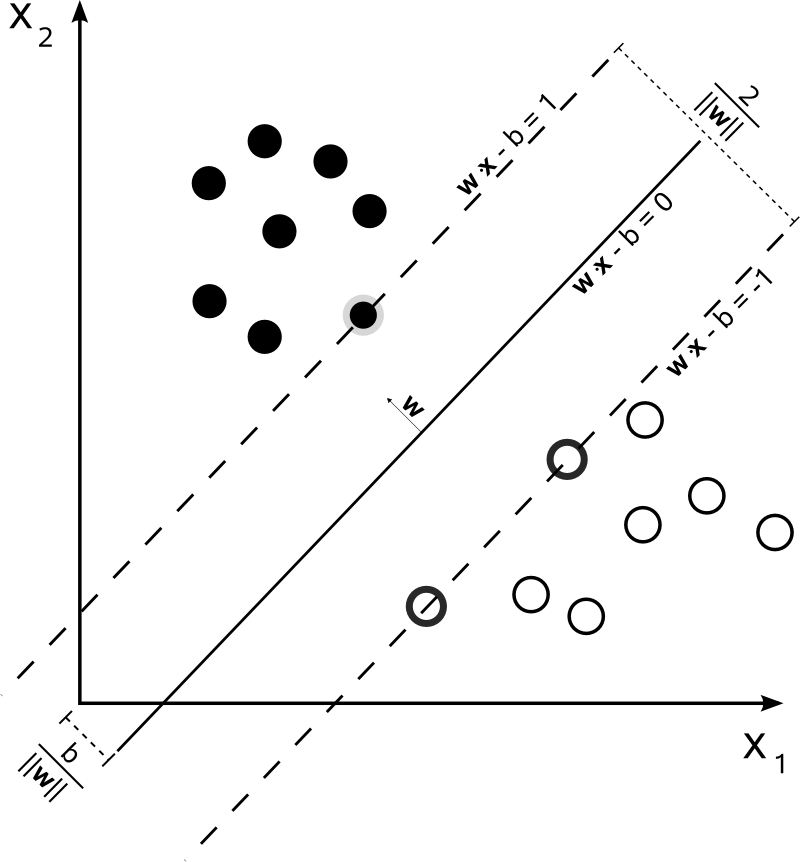
When writing computer programs, the two fundamental parts are what to do and how to do it. Algorithms essentially tell a computer how to accomplish the assigned task, and there are multiple ways to do a task, and data scientists use the type of algorithms based on the task at hand and the resources (time & cost) that each type of algorithm may consume.
The type of algorithm that you will use while solving data science problems will depend on the type of learning that your machine will perform. It can be supervised, unsupervised, semi-supervised, or reinforcement learning.
Depending on the type of machine learning, algorithms are usually grouped according to the following categories.
- Association rule learning
- Clustering
- Regression
- Artificial Neural networks
- Ensembling
- Instance-based method
- Decision tree learning
- Deep learning
- Regularization
- Kernel methods
- Bayesian
- Dimension reduction
Mirko Krivanek posted an excellent explanation of algorithms within each of these categories.
Artificial intelligence and machine learning AI/ML
These are somewhat controversial areas of big data applications ( read Stephen Hawking, Vernor Vinge and Elon Musk on their criticism of Artificial Intelligence) but an essential component for your data science career. Most people confuse AI with a lot of things, from robots to self-driving cars to anything that’s beyond their computing genius.
Like its sister concerns Big Data and the Data science, AI is also a broad concept and a blanket term. The best that a human did to explain this oft-confused-muddled term was Tim Urban. he divided AI into three broad categories:
- AI Caliber 1) Artificial Narrow Intelligence (ANI)
- AI Caliber 2) Artificial General Intelligence (AGI)
- AI Caliber 3) Artificial Superintelligence (ASI)
Having conquered the AI caliber 1, we are currently in the AI caliber 2 phase but still far from the AI caliber 3.
Distributed computing
A distributed system is a software system in which components located on networked computers communicate and coordinate their actions by passing messages. The components interact with each other in order to achieve a common goal. Hadoop, HBase, Hive, Pig, Flink, all tools that are resource efficient are used in distributed computing projects.
Databases
Deciding which database to use out of all available, the decision comes to the end goal that a data scientist has to achieve. Let CAP theorem be your guide. CAP theorem asserts that we can only have two out of the three, consistency, availability, and partition tolerance. To get a handle on types of databases available within the NoSQL family, get familiar with the following types.
- Key-value pair databases (Couchbase, Cassandra)
- Document databases (MongoDB, CouchDB)
- Big table databases (HBase)
- Graph databases (Neo4j, OrientDB)
Want to delve deep into the database layer, check this post by Andrew Oliver.
Programming
C++, Java, Python, R, Hascal, Scala
3. Operations
Continuous integration
It becomes a core challenge in large-scale and geographically 
distributed big data implementations to integrate all changes.
This can be done using Ansible, Docker, Jenkin, ELK-Elasticsearch, Logstash, Kibana.
Infrastructure management
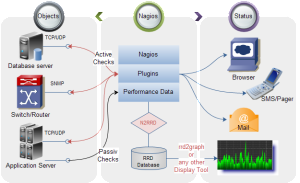
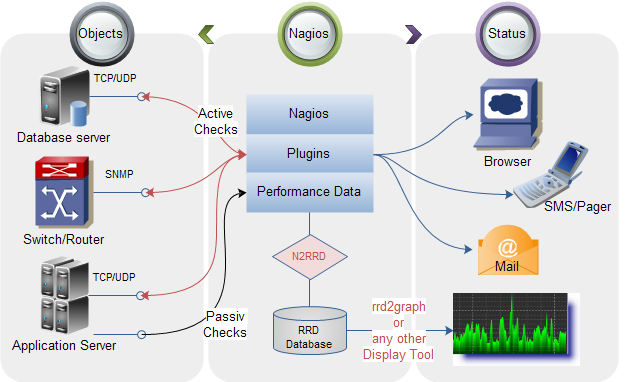
You’ll have to deal with big data infrastructure management issues. Here, the knowledge and experience in hardware, networking protocols, Unix/Linux, and the OS (Operating System), Scalability, reliability & efficiency comes in handy.
Specific tools you can use to tweak infrastructure are Nagios, Fiddler, Zenoss Core, Splunk.
4. Security
The seven rings of security within a complex implementation of a big data project.
T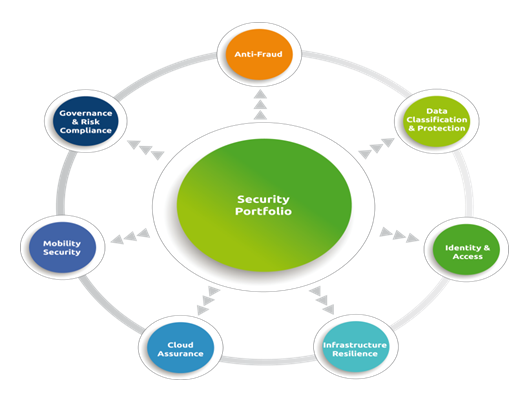 ools used to secure big data applications include Truecript, Wireshark, OpenVAS, and BigSnarf.
ools used to secure big data applications include Truecript, Wireshark, OpenVAS, and BigSnarf.
Before you commit to learning all these skills at each layer, just pause for a moment and consider what you want to achieve. No one person will be able to delve deep into each layer or each skill I have listed.
What you can do is to develop a clear understanding of the relationship of each layer to the other. This will help you develop your own niche of skill-set.
Related Posts
 Hadoop Foundation III: Laying the architecture & tools that compliment Hadoop
Hadoop Foundation III: Laying the architecture & tools that compliment Hadoop Hadoop Foundation II: What type of data Hadoop can help me with?
Hadoop Foundation II: What type of data Hadoop can help me with?- Data Scientists and Justin Trudeau: 5 amazingly common things between the Canadian PM and data scientists
 Big Data – Weekly News
Big Data – Weekly News Big Data – Weekly news
Big Data – Weekly news Big Data – Weekly News
Big Data – Weekly News