
Hadoop Ecosystem helps a multinational automobile manufacturer in rapid soft-prototyping [Case Study]
Customer Background
Customer Profile: German multinational automotive manufacturer
Country of Deployment: Germany
Industry: High-tech. Automobile Manufacturing
Challenge
The automotive company planned to execute the soft-prototyping of all the automobile models that it produced throughout its globally located factories. A major challenge was designing the simulation process of the whole manufacturing process of the automobile based on numerous criteria such as:
- Noise
- Vibration
- Heat
- Safety
- Materials Composition
- Crash
- Operational Planning
- Material Requisition, etc
The most essential function for the client was simulating the whole production process before a unit goes into production. The major challenge was that real-time production data be used for creating a simulated environment. It was important to have access to real-time data and, that too from multiple sources, that would make it possible for the client to perform pre-determined quality-management analytics for adjusting input values. The ability to respond in least possible time shall give edge to take certain decisions, thus helping taking competitive market edge.
Another related challenge was to perform the simulation process across various product lines in multiple manufacturing facilities across the globe. The production and quality management team leads had to ensure that the product quality is consistent with Six-Sigma, lean and TQM standards. Datasets of all quality related variables (noise, vibration, materials composition to name a few) had to be fed. A unique challenge remained as to managing the high volume, high-variety and high-speed data that were to contribute in the simulation process. The client required a highly scalable process simulation solution that could be used for each product line of the company.
Solution
Allied Consultants proposed the implementation of Hadoop ecosystem and other open source tools to develop a highly visual and scalable big data solution. To make the solution relevant to client’s quality needs, the simulation process needed to be fed data from multiple sources including those already used by the client.
The solution was designed with respect to 4 phases:
1. Product architecture
Each department (product design, operations and IT) had set metrics and KPIs that were to be incorporated within the solution architecture. Operations function had to design human resource demand and supply according to the production planning process.
Some legacy systems of the client were only used for fetching data without any subsequent use in solution modules.
A core component of architecture was to embed the ability of real-time warning: whether there was some kind of issue in operations (malfunction, lack of material) or some sort of infrastructure was under severe cognition, and thus was affecting the overall performance.
The data generated by apps and network helped in identifying if some protocols were not complied with.
NoSQL was used to store and retrieve data that was critical and required as real-time in-memory function for the continuity of production.
SQL on hadoop was used for some specific metrics such as in value stream mapping that does not require real time analytics. Since operations in-charge had to analyze that how many equipment were not compliant during the shift’s production time, the queries were designed in SQL.
2. Selection of frameworks for adaptability
Some in-house frameworks such as lean manufacturing and six sigma were already used by the client and required incorporation in the new environment. The main data centers were located at Germany, USA and Asia Pacific region. ZooKeeper was used to maintain configuration information, naming, provide distributed synchronization, and deliver the group services. Another open-source software Nagios was used to monitor computer systems of client, network monitoring and infrastructure monitoring. More network monitoring and automation solutions, from companies like Indeni, might be utilized to improve the function of networks.
3. Security mechanism
The solution was designed to ensure three broad levels of security i.e. data security, infrastructure security and Integration security.
Application, data and integration security was ensured at our end whereas infrastructure security was solely client’s responsibility due to the transnational and vast operations of the company.
4. Scalable technology infrastructure
Lambda Architecture was tweaked and implemented for, as it divides the incoming data stream into batches of data based on either compute intensity or communications intensity. Since Lambda architecture handles both stream-processing and batch-processing data, the solution allowed the client to balance the fault-tolerance, latency and throughput.
This saved additional complexity: keeping resources busy while certain matters/nodes would be under pressure when another master/nodes would be under-utilized. Before presenting the results to the quality management team lead, both the batch and live-stream data were joined. The proof-of-concept showed 30% improvement over conventional methodology adopted.
The development part of solution consisted of three main operations; a) scaled agility, b) iterative development and c) DevOps based deployment.
a) Scaled agility
- Delivered successful PoC
- QA assessed the solution solution compatibility
- Even if the priorities changes for deliverable, the overall performance nor the committed time lines change.
b) Iterative development
Following the agile SDLC, the following were accomplished in close liaison with the client:
- Development of modules
- Simulation module
- Noise control module
- Heating & Cooling Optimization module
- Crash & Safety Analysis module
- Production planning module
- Materials planning module
c) Deployment through virtual live streaming
The complexity in deployment lay at many ends: certain clusters were available only for performing engineering computations, thus compute intensive, while other needed only as child nodes to pass-on the data transaction information.
It was proposed that multiple masters/nodes be created to visualize scenario for real processing and all traffic be direct to the list of those clusters, within Docker/VM environment, before deploying the final solution to live & dedicated data center(s).
Business Benefits
The major business benefit was the ability to visualize the whole production planning. The change of parameters and their effects throughout the system and their implication on financial aspects of the production process. It also helps identify the tipping point beyond which a collapse of function would have been imminent. Another major advantage that client reaped was a reduction in the per-unit cost of each model that was produced post-implementation of the solution. Reworks on new models were also reduced significantly.
- Optimal material planning and requisition
- More safer and fuel efficient vehicles
- Preemption of process collision & collapse instances
- The reduction in the per-unit price of ready-to-market models (based on changes in materials composition)
- Reduction in reworks
Technologies
JEE | C++ | MapReduce | Hadoop |
| PostgresSQL | Cassandra | HBase | Hive |
| Apache Shark | Pentaho | R | MongoDB |
| Python | Zookeeper | Nagios | Talend |
You may like:
Key Questions to self-discover a company’s Big Data maturity stage
Downloadable template for live Big Data pilot project
Big Data Training Part 1, Part 2 & Part 3
Related Posts
 Risks in Software Development and How to Mitigate Them
Risks in Software Development and How to Mitigate Them SOAP Training
SOAP Training Interview with the founder of blender
Interview with the founder of blender Four Phases To Developing the Ideal Mobile Apps
Four Phases To Developing the Ideal Mobile Apps Microsoft reveals 2 types of partners: modern & dated. Which one are you?
Microsoft reveals 2 types of partners: modern & dated. Which one are you?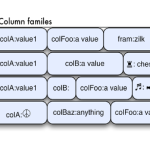 APACHE CASSANDRA DATABASE 4 PROBLEMS THAT CASSANDRA DEVELOPERS & ADMINISTRATORS FACE
APACHE CASSANDRA DATABASE 4 PROBLEMS THAT CASSANDRA DEVELOPERS & ADMINISTRATORS FACE